Như đã đề cập ở bài trước, Big Data là một tập hợp dữ liệu rất lớn và / hoặc rất phức tạp đến nỗi những công cụ, kỹ thuật xử lý dữ liệu truyền thống không thể nào đảm đương được. Vậy những kỹ thuật hiện đại nào sẽ giải quyết được vấn đề của Big Data? Ở bài này mình xin giới thiệu về Hadoop, một framework được dùng phổ biến nhất để giải quyết các bài toán về Big Data.
Hình ảnh về Apache Hadoop
1- Tại sao cần Hadoop? Hay Hadoop ra đời để giải quyết vấn đề gì?
Một hệ thống với dữ liệu lớn cỡ hàng Peta Bytes, thì rõ ràng việc vận hành, thực thi xử lý dữ liệu là rất khó khăn. Để giải quyết vấn đề đó, người ta chỉ có cách là làm thế nào tăng được khả năng xử lý hệ thống máy tính lên. Và có 2 phương án được đưa ra là Scale Up và Scale Out. Scale Up là phương án làm tăng khả năng xử lý của máy chủ lên bằng cách tăng CPU và tăng bộ nhớ (RAM). Còn Scale Out là phương án làm tăng khả năng xử lý của hệ thống máy chủ bằng cách tăng số lượng máy chủ lên, cấu hình mỗi máy chủ không yêu cầu cao.
Nội dung dưới đây sẽ liệt kê ra những ưu nhược điểm của 2 phương án này:
Scale Up
-
Ưu điểm:
-
Việc thực thi là dễ dàng. Đơn giản chỉ là lắp thêm (hoặc thay thế) CPU và RAM cho máy chủ.
-
Vì số máy chủ không đổi nên sẽ không mất thêm chi phí license cho các phần mềm chạy trên đó.
-
Việc quản lý, vận hành máy chủ không thay đổi so với trước do số lượng máy vẫn như cũ.
-
Nhược điểm:
-
Việc tăng hiệu năng cho 1 máy chủ là có giới hạn. Bạn không thể muốn lắp thêm bao nhiêu CPU, bao nhiêu RAM cũng được.
-
Chi phí cho linh kiện CPU, RAM có cấu hình cao ngày càng đắt đỏ.
-
Việc vận hành hệ thống trên 1 máy chủ cũng gặp phải nhiều rủi ro khi máy đó bị dừng thì hệ thống cũng sẽ ngừng hoạt động.
Scale Out:
-
Ưu điểm:
-
Việc tăng hiệu năng của hệ thống gần như không giới hạn bởi chỉ cần tăng máy chủ là tăng được hiệu năng của hệ thống.
-
Có thể tận dụng được những máy chủ cấu hình thấp, rẻ tiền.
-
Một vài máy chủ ngừng hoạt động thì hệ thống vẫn có thể hoạt động được bình thường mà không bị gián đoạn.
-
Nhược điểm:
-
Việc tăng số lượng máy làm tăng số lượng license của các phần mềm trên các máy chủ.
-
Việc quản lý một hệ thống với số lượng lớn máy chủ là cực kỳ phức tạp. Hãy tưởng tượng nếu vận hành 1 hệ thống lên tới hàng nghìn máy chủ thì bạn sẽ vất vả đến cỡ nào.
-
Việc cài đặt, triển khai một hệ thống phần mềm hoạt động trên nhiều máy chủ cũng không hề đơn giản.
Nhìn vào những ưu nhược điểm trên, rõ ràng là phương án Scale Out có lợi điểm hơn nhiều so với phương án Scale Up trong việc tăng hiệu năng xử lý của hệ thống máy chủ.
Ngoài những so sánh trên, một khó khăn nữa cũng cần phải kể đến là tốc độ truyền tải (đọc, ghi) của của ổ cứng. Với tốc độ truyền tải dữ liệu của ổ cứng hiện tại vào khoảng 100MB/s thì việc đọc 1TB dữ liệu sẽ mất hơn 10,000 giây (khoảng hơn 2 tiếng), với 1PB dữ liệu sẽ mất hơn 10,000,000 giây (khoảng 115 ngày). Với tốc độ đọc dữ liệu như vậy thì cho dù triển khai phương án Scale Up với máy chủ cấu hình khủng đến mấy thì cũng không thể đáp ứng được yêu cầu sử dụng trong thực tế. Nói một cách cụ thể, người dùng không thể đợi 115 ngày để có được kết quả báo cáo từ việc phân tích 1PB dữ liệu. Khi triển khai theo mô hình Scale Out thì việc đọc dữ liệu là song song, giả sử bạn xử lý 1PB dữ liệu trên một hệ thống gồm 1000 máy chủ thì việc đọc dữ liệu có thể sẽ nhanh hơn 1000 lần, nói cách khác thời gian người dùng phải chờ có thể giảm từ 115 ngày xuống còn hơn 2 tiếng.
Như vậy, để giải quyết bài toán Big Data chỉ có phương án duy nhất là hệ thống phải được triển khai theo mô hình Scale Out. Và Hadoop là một framework cho phép thực thi theo mô hình này. Hơn thế nữa, Hadoop còn cho phép người quản trị quản lý, cài đặt & vận hành một cách khá dễ dàng thông qua giao diện UI và Command line.
2 - Thành phần của Hadoop
Hadoop bao gồm 2 thành phần cơ bản là: HDFS & MapReduce
-
HDFS (Hadoop Distributed File System)
-
Là File System
-
Được xây dựng trên Java
-
Cho phép sử dụng (truy xuất) nhiều ổ đĩa như là 1 ổ đĩa. Nói cách khác, developer có thể sử dụng một ổ đĩa mà gần như không bị giới hạn về dung lượng, không còn khái niệm hoặc phân biệt ổ đĩa này hay ổ đĩa kia nữa. Muốn tăng dung lượng chỉ cần thêm node (máy tính) vào hệ thống.
-
Cho phép đọc (read), ghi (write), không ghi thêm (append) được
-
Kích thước 1 block thông thường là 64MB, kích thước này có thể thay đổi được bằng việc cấu hình
-
Đã hỗ trợ sẵn cơ chế replication (do đó không cần sử dụng RAID)
-
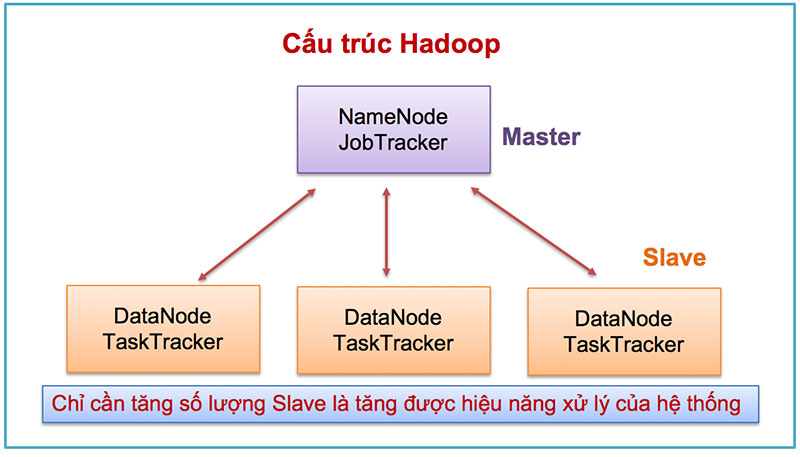
Có 2 loại: Namenode (trên máy chủ Master) và Datanode (trên máy chủ Slave)

Cơ chế replication 3 trong Hadoop
-
MapReduce
-
Là một hình lập trình được Google đưa ra năm 2004
-
Xây dựng trên nền tảng Java
-
Bao gồm 2 function là Map và Reduce
-
Có hai loại node điều khiển quá trình thực thi công việc là JobTracker và TaskTracker
Luồng xử lý của MapReduce
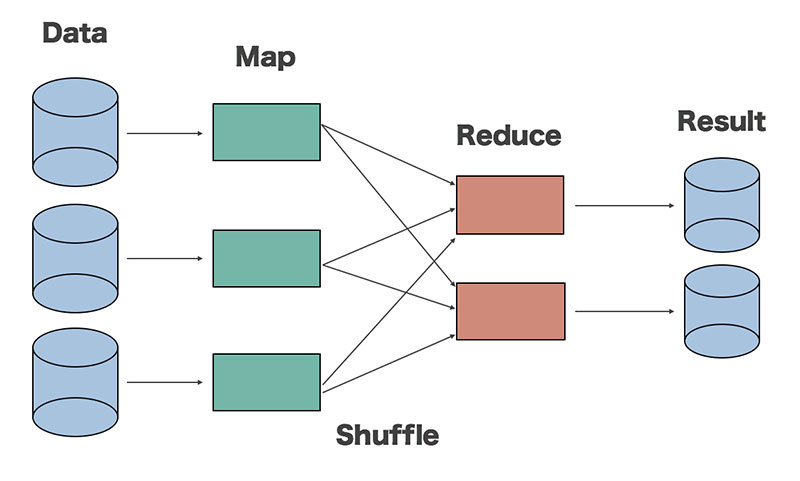
Để dễ hiểu hơn, hãy cùng xem ví dụ WordCount sau đây. WordCount là bài toán đếm tần suất xuất hiện của các từ trong đoạn văn bản. Hãy xem quá trình xử lý bài toán WordCount với mô hình lập trình MapReduce như hình dưới đây.
Bài toán WordCount với MapReduce
Với hàm Map:
-
Đầu vào là 1 đoạn văn bản
-
Đầu ra là các cặp <word, 1>
Hàm Map được thực hiện song song để xử lý các tập dữ liệu khác nhau.
Với hàm Reduce:
-
Đầu vào có dạng <word, [list]>, trong đó list là tập hợp các giá trị đếm được của mỗi từ.
-
Đầu ra: <word, tổng số lần xuất hiện của từ>
Hàm Reduce cũng được chạy song song để xử lý các tập từ khoá khác nhau.
Giữa hàm Map và Reduce có một giai đoạn xử lý trung gian gọi là hàm Shuffle. Hàm này có nhiệm vụ sắp xếp các từ và tổng hợp dữ liệu đầu vào cho Reduce từ các kết quả đầu ra của hàm Map.
Như vậy, cấu trúc của một hệ thống Hadoop có thể biểu diễn như hình bên dưới:
Cấu trúc hệ thống Hadoop
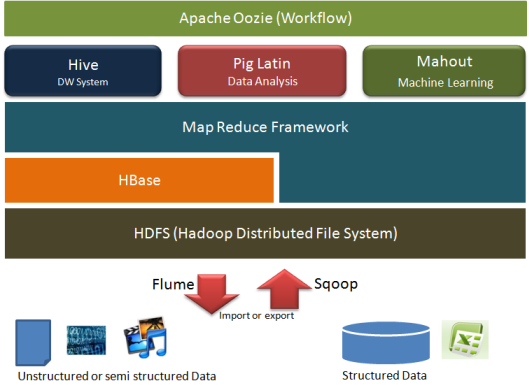
3 - Hệ thống Ecosystem hỗ trợ Hadoop
Để triển khai một hệ thống ứng dụng dựa trên Hadoop, ngoài thành phần cốt lõi là Hadoop ra người ta cũng thường sử dụng các thành phần khác nữa gọi là Hadoop ecosystem.
Hadoop Ecosystem
Các thành phần trong Hadoop ecosystem được liệt kê ra như dưới đây:
-
HBase (KVS): là một hệ quản trị CSDL NoSQL
-
Hive: hỗ trợ thực thi một chương trình MapReduce dưới dạng SQL, cách viết tương tự các câu lệnh SQL.
-
Impala: tương như Hive, nhưng tốc độ xử lý tốt hơn
-
Pig: nền tảng giúp cho việc xây dựng chương trình MapReduce đơn giản hơn
-
Mahout: nên tảng thực thi các thuật toán máy học (machine learning)
-
Hue: là giao diện Web điều khiển, quản lý Hadoop
-
Spark: cho phép thực thi các chương trình MapReduce trong bộ nhớ RAM nhằm tăng hiệu năng xử lý
-
Zookeeper: là dịch vụ trung tâm quản lý các thành phần trong hệ thống Hadoop. Nếu bạn để ý thì sẽ thấy rằng tên các thành phần trong Hadoop ecosystem hầu hết là tên các con vật, Hadoop ecosystem giống như một vườn thú, và Zookeeper chính là người quản lý vườn thú vậy.
-
Oozie: dịch vụ quản lý các job
-
Asakusa: là framework cho phép thực thi các ứng dụng dang batch trên Hadoop
Chi tiết về một số thành phần trên mình sẽ giới thiệu ở những bài viết tiếp theo.














")













")
{kind=link}
{kind=link}
{kind=link}